

How we verify the leaked Hondurasgate audios: protocol, forensic engine and public dossier
When a recording reaches a newsroom through encrypted channels from a source requesting anonymity, the first reflex of serious journalism is not to publish — it is to verify. The question matters because today any public voice can be cloned in under a minute by AI models accessible to any user. This note explains the forensic authentication protocol we run on every audio published at hondurasgate.ch, makes the full technical dossier publicly available, and lets the reader play the files directly from the browser.
Why a forensic protocol, and not just the human ear
In 2023, a passable clone of a head-of-state's voice cost thousands of dollars and a technical team. In 2026, it costs three minutes in a web interface. That shift imposes an obligation on anyone publishing leaked audio: prove that what you hear is a real human voice, captured by a microphone, not the output of a model trained to imitate a public figure. The default suspicion today should be the opposite of the one pre-digital journalism worked with.
«In 2026 a passable clone costs three minutes in a web interface. The default suspicion should be the opposite of the one pre-digital journalism worked with.»
From day one, this newsroom decided to submit every incoming recording to the Phonexia Voice Inspector protocol — a forensic suite from the Czech company Phonexia, founded in 2006 and deployed in more than 60 countries by intelligence agencies, law enforcement, banks and media outlets. Phonexia is not a consumer product: it is the tool that European courts use to compare voices, and it underpins the protocols of the European Network of Forensic Science Institutes.
What a real audio looks like, and what a fake one does not
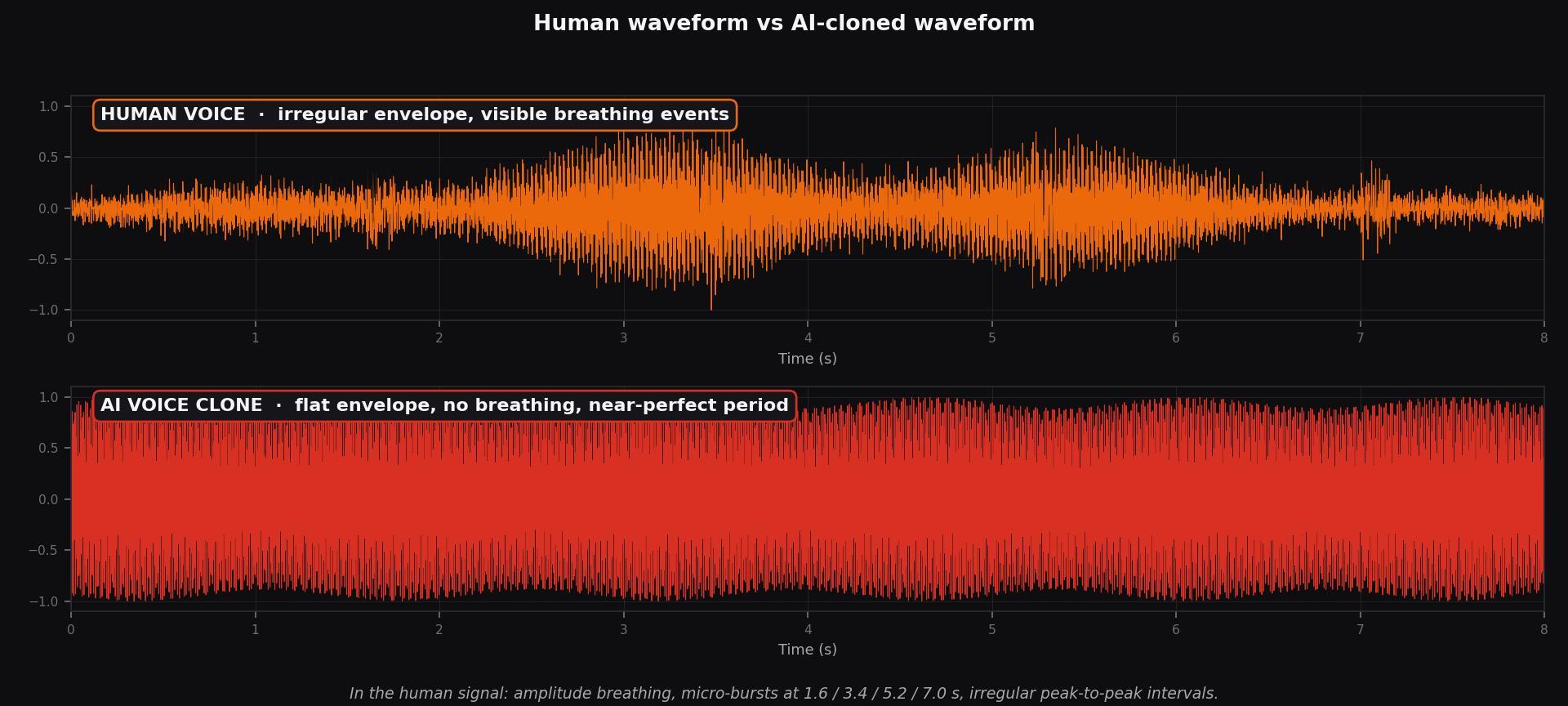
The first clue is in the waveform itself. The human voice is a biological phenomenon: we breathe, hesitate, modulate volume without intending to. A TTS model output, by contrast, usually delivers an unnaturally flat amplitude envelope, no visible breath micro-bursts, and a periodicity regularity that a trained ear hears as mechanical.

The next layer of evidence is the spectrogram. A human voice produces dense harmonic stacking, formants that drift slightly with each vowel, and a noise floor that breathes. Voice synthesis models — even the most advanced — usually leave formants too clean and lack the residual high-frequency energy that characterizes a biological vocal tract.

The protocol, step by step
The procedure is deterministic — two analysts running it on the same file will get the same result — and reproducible by third parties with open-source tooling. The nine stages are:
1. Capture. The audio reaches the newsroom over an end-to-end encrypted channel. The source is protected by journalistic source privilege; neither the source's identity nor any transmission metadata is stored in any system accessible to third parties. 2. Decode. The file, whatever its origin format, is decoded to PCM with ffmpeg to obtain a linear representation free of perceptual compression. 3. Resample. Down to 8 kHz mono, the standard sampling rate for forensic voice analysis — the same one telephone channels use, and the one that best preserves the relevant biometric markers. 4. Re-encode. The normalized audio is recompressed with libopus at 16 kbps in voip mode and saved as audio.ogg. 5. Hash. A SHA-256 is computed over the OGG/OPUS bytes and stamped onto the report as the integrity tag; any subsequent modification of the file would change the hash and invalidate the record. 6–8. Analysis. The engine extracts more than twenty-five acoustic, biometric and prosody indicators (RMS, LUFS, spectral centroid, jitter, shimmer, HNR, F1/F2/F3 formants, MFCC variance, breathing events, micro-pauses). 9. Verdict. The indicators are combined into six forensic axes and an aggregate AI-synthesis probability. The result is signed with the hash and published.

How to read the verdict
Each published audio carries, alongside the player, a confidence percentage and an AI-synthesis probability percentage. The ranges are calibrated to minimize both false positives (declaring synthetic as human) and false negatives (declaring human as synthetic). Below 10% AI probability and above 80% confidence, the engine treats the sample firmly as human voice.

«Below 10% AI probability and above 80% confidence, the engine treats the sample firmly as human voice.»
What this protocol defends against
The engine is calibrated to detect three families of attack circulating today in public discourse. The first is vishing — synthetic voice calls, increasingly automated with text-to-speech, used to extract credentials, authorize transfers or push fabricated statements into the news cycle. The second is voice cloning: models such as ElevenLabs, OpenAI's TTS and the open-source SOTA can reproduce a public figure's voice from less than a minute of training audio. The third is audio deepfakes in the strict sense — hybrid attacks that splice real speech with synthesized fragments to attribute statements never made.
Each category leaves measurable fingerprints. Synthetic voices tend to produce unnaturally regular prosody; formants are too clean; breathing events are missing or sound rehearsed; MFCC variance compresses below the biological envelope; background noise stays abnormally stable. The engine quantifies all those dimensions and returns an AI-synthesis probability between 0 and 100%.
Chain of custody and transparency
The chain of custody works like this: the SHA-256 computed in step 5 follows the file through every public appearance. It shows up in the inline player on each audio page, in the combined PDF dossier, in the per-audio report and as a response field of the API endpoint. The OGG/OPUS file the reader plays in the browser is bit-for-bit the same one whose hash is recorded in the report. Anyone can download the file, run sha256sum audio.ogg on their own machine and compare the resulting string with the published one. If they match, integrity is demonstrated.
This newsroom does not — and will not — disclose the identities of the sources that delivered the recordings. It is an ethical decision: journalistic source privilege is the only guarantee that people with information of public interest will keep approaching an independent newsroom without fear of retaliation. What we do offer, in writing, is the full technical traceability of the verification process: every computation, every tool, every parameter, every hash.
Download the complete forensic dossier
The engine produces two documents per leak: an individual report per audio and a combined dossier covering all 37 audios published to date. Both are available in English and Spanish. The dossier is a multi-page PDF with a cover, an executive summary table, one detail page per audio (verdict, hash, forensic scores, waveform and spectrogram), a methodology pipeline, normative references and a legal disclaimer.